For me, the best way to learn anything is to do a project on it. I start by learning the bare minimum required to start the project and then keep on learning on the way. I read articles and papers on the topic side by side to learn the subject in a more idiomatic way. I didn’t start this project to dive into NLP but my aim was to learn how RNNs and LSTMs work. Any problem with sequential data would have done. I finally decided to try out Sentiment Analysis using RNN and LSTM as words in our sentences are also sequential. I didn’t want to use any conventional datasets (like IMDB) for this task and downloaded the Amazon books reviews.
The first task I do when given any dataset is data exploration. The data was in a JSON file and each review was in the following format:
{
"reviewerID": "A2SUAM1J3GNN3B",
"asin": "0000013714",
"reviewerName": "J. McDonald",
"helpful": [2, 3],
"reviewText": "I bought this for my husband who plays the piano. He is having a wonderful time playing these old hymns. The music is at times hard to read because we think the book was published for singing from more than playing from. Great purchase though!",
"overall": 5.0,
"summary": "Heavenly Highway Hymns",
"unixReviewTime": 1252800000,
"reviewTime": "09 13, 2009"
}Clearly, I only need the reviewText and overall fields. The overall field is the rating, which will help me know the sentiment associated with the review. The ratings are on a scale of 1-5 (integers only). The following graph shows the distribution of ratings in the dataset:
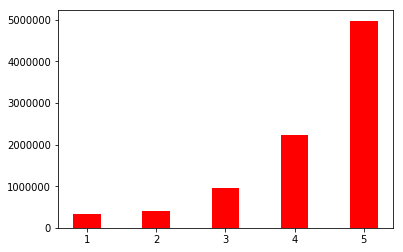
As visible, this is a quite imbalanced dataset. This can either be because people don’t take the pain to write a bad review or because very few books out there are bad. I prefer to believe the former given that even Chetan Bhagat books have good ratings on Amazon. So, clearly there is a selection bias present in the dataset. To deal with it, either you can upsample the minority class (negative sentiment) or downsample the majority class (positive sentiment) i.e. apply Heckman correction. But before that, the question arises: which ratings will be designated as negative and positive reviews. I know that 4, and 5 are good reviews and 1, and 2 aren’t. What about 3? Since this dataset has about 8 million reviews, I can let go of the reviews with a rating of 3. I do this because this integer has a different meaning for everyone i.e. for me, 3 means neither good nor bad but for someone else, it may mean extremely bad or quite good. Thus, either I can figure out a way to deal with this user bias or make an even intelligent choice to just let it go. The following graph shows the distribution of positive sentiment (class=1) and negative sentiment (class=0) after removing 3:

This is a classic example of having more data vs. having the right data. The underlying data generating distribution will not be altered if I simply remove the rating 3 whereas keeping 3 may lead to a decrease in variance and an increase in bias and I can’t know without making a model if the increase in bias will be offset by the decrease in variance. The minority class does not even belong to the 0.1 quantile of the data. Thus, affter removing 3, I downsampled the reviews belonging to the majority class and made them equal in number to the minority class. Now, I have 1.4 million reviews equally distributed between positive and negative sentiments. I make a 75%/15%/10% train/validation/test split (random split).
In NLP, we want to make models that generate, understand, and work with human languages. But the challenge is that our computers understand only numbers and we communicate with words and sentences. Many techniques have emerged to convert characters/words/sentences to a format which our systems can comprehend. The distributional hypothesis is the foundation of how word vectors are created:
a word is characterized by the company it keeps – John Rupert Firth
I used torchtext to tokenize the reviews (using spacy tokenizer) and learn the vocabulary out of the reviews. The vocabulary is basically a lookup table where each unique word in the dataset is assigned a corresponding index. To not have very sparse data, I keep only the top 25000 most frequently used words in the vocabulary. Words in sentences which don’t appear in the vocabulary are replaced by an ‘unk’ token and sentences with lengths less than the set length are padded with a ‘pad’ token.
The first model I used was a simple RNN. I used three layers, first one being an embedding layer (to convert the one hot encoding vectors of a sentence to a dense embedded vector output), followed by an RNN and a linear layer at the end. I used accuracy as a measure to evaluate the performance of the model. The naive model which rates everything as positive or negative will have 50% accuracy because of balanced classes in the data. The validation accuracy I got after training for 5 epochs was 51% (ugh!!).
Next, I decided to move to LSTM to combat the vanishing gradient problem of RNNs. LSTMs overcome this by having an extra recurrent state which can be thought of as the “memory” of the LSTM - and they use multiple gates which control the flow of information into and out of the memory. I used a bidirectional multilayer LSTM instead of the RNN keeping all other layers same in the above model. The concept behind bidirectional LSTM is simple: in addition to processing the words sequentially from start to the end of the sentence, they also process the sentence backward. And voila! the accuracy increased to 95%.
To test if the model works only on sentences relating to books or can generalize to other areas as well, I passed some general sentences to the model:
- Our economy is in the middle of a revolution. Demonetization, the introduction of GST and recapitalization of banks may prove to be a game changer. Sentiment predicted: Positive
- We found a cool bar yesterday with a rooftop, we should go there!. Sentiment predicted: Positive
- Only one person at CDS this time. Sentiment predicted: Negative
I have put the code on GitHub. You can refer to this code if you want to know how to convert a pandas dataframe to a torchtext tabular dataset.
Merry Christmas everyone!
Thanks,
Ashwin